文本大數據深度挖掘,你掉了多少坑?
當前談到網絡文本大數據處理,一般多提及強大的搜索引擎、精準的自然語言處理、前沿的機器學習、神經網絡、人工智能和獨家算法等,試圖通過這些技術可以實現精確預測、數據整合、對相關關係的探究。然而,大數據並非無所不能,尤其是當前對於網絡大數據的理解和應用中,存在不少的誤區。
2017年10月29日,澳門互聯網研究學會會長張榮顯博士在“10th PRAD國際學術論壇·2nd PRSC學術年會暨4th戰略傳播與公共關系工作坊”的主題工作坊“展望公關研究:理論拓展與方法創新”上進行題爲《大數據研究方法:如何進行傳播內容的深度文本挖掘》的演講,介紹了全新的網絡大數據研究方法。

張博士指出,當前有觀點認爲,網絡大數據可以做到精確預測。然而,在實際應用中,大數據的算法、語義分析等,距離現實尚有一段距離,水平待有提高,加上歧義和無關數據的干擾,也在影響著數據分析結果的準確度。還有觀點認爲,當數據量足夠大的時候,數據便可以自己說出結論等,這是非常危險的論斷。這些誤解都忽略了文本數據本身的非結構化特徵,以及文本背後的語義和語境的複雜性。


演講之始,張博士談及分享目的,明確大數據研究方法的研究對象,是針對傳播內容進行深度文本挖掘,主要指傳播內容方面的文本數據,即文字,圖片,語音,視頻等。通過分析當前業界處理文本數據的方式,尋求我們所面臨的問題的解決方法,在學術上探究新的研究路徑——利用大數據技術來輔助在線內容挖掘與分析。
文本大數據挖掘思想和分析技術
文本大數據挖掘金字塔的基礎是符號/信息,也是當前業界處理文本數據的主要方式,集中於收集文本、資料歸類及信息可視化方面,通過搜索、電子剪報系統及輿情/品牌監測系統得以實現。除了信息層面之外,可進一步提升內容及結果的挖掘,至社交網絡和語義分析層面。最終在學術研究或政策決策等方面得出有意義的洞察,需做出有價值的決策,張博士用文本大數據挖掘金字塔的概念來闡述。
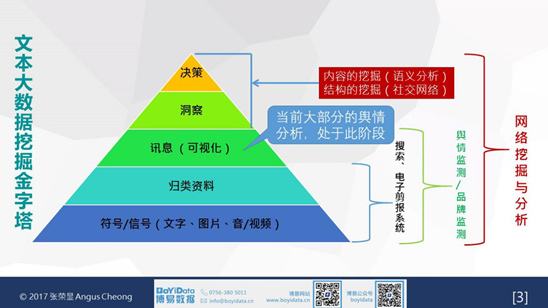
主流的處理大數據的分析技術主要是針對兩種數據類型——數字型數據(結構化的數據)和文本型數據(非結構化的數據)。數字型數據的分析技術包括線上分析處理、數據挖掘、統計分析等;文本型數據的分析技術包括文本分析、網絡挖掘、網絡分析、機器學習和情緒分析(sentiment analysis)等。

當前輿情大數據監測策略
目前輿情大數據監測系統的策略主要有資訊提取,文本摘要和情緒分析三部分。處理網絡數據的情況,絕大部分是基於描述性和探索性的單變量分析,包括傳播來源(網絡數據來自具體的媒體來源,如社交網站、新聞網站、博客、論壇等)、傳播量度(網絡輿情或口碑的聲量,以描繪事件的發展趨勢;詞雲圖以字體在圖中的大小來表示聲量大小或關注點等)、傳播內容(網絡輿情所涉及的話題、人物、機構、品牌等)、傳播特徵(以數量來描繪輿情話題的走勢、事件發生的路徑等,以解釋傳播過程和特徵)、傳播力度(點讚量、跟帖量、分享量、閱讀量、排行榜等,還有參與度、曝光量、KOL等,以多項參數來綜合解釋輿情的傳播力度)和傳播效果(正負面情緒、分類情緒如快樂、悲傷、厭惡、恐懼和憤怒等)。

大數據最顯著特徵:非結構化
不同於傳統調查意義上的小數據,大數據時代的網絡數據是非結構化的、開放式的。傳統的5W1H中的來源、時效、身份、焦點、原因等,容易在網絡文本中被淹沒不見。因此,我們需要企圖通過某些方法,在分析中找回5W1H。


社會實證研究深度需求
社會實證研究的核心問題是研究變量之間的差異和關係,包括交叉和聚類,相關和因果關係等,這也是研究網絡輿情必須回答的問題,然而卻是當前機器無法解決的文本數據挖掘的問題,因此要突破基本的描述性和探索性,深入到解釋性的程度,是學術研究或商業決策的努力方向。
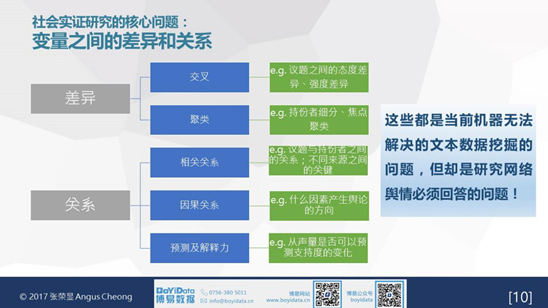
更進一步,研究需要對系統變量和編碼變量進行深度挖掘。這裡,系統變量是指網絡技術可抓取的非結構化的數據,可以轉化成結構化的數據而形成的變量,這部分可由技術層面解決,由程序進行自動轉化。目前,市面上的眾多輿情分析多數以系統變量爲主。我們提出的編碼變量,則是指由研究人員自行設定的變量,即根據具體的研究目的、研究問題及需要測量的概念而設計的。要實現對研究結果的描述性和探索性層面的突破,達到解釋性的深度要求,就要將兩者有效結合,可將系統變量和編碼變量進行交叉分析,實現從發現洞察到預測未來的目標。

全新的網絡大數據研究方法:
大數據技術輔助在線內容分析法(Online Content Analysis)
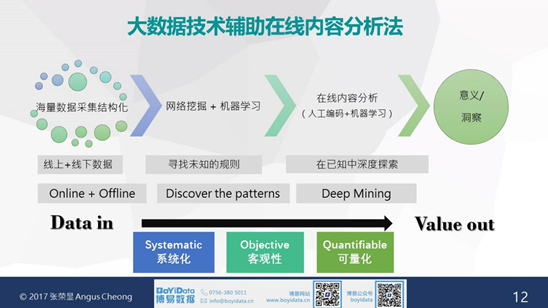
基於以上論述,張榮顯博士提出全新的網絡大數據研究方法——大數據技術輔助在線內容分析法,通過將海量數據採集結構化、網絡挖掘結合機器學技術、在線內容分析(人工編碼、機器編碼及機器學習),最終實現挖掘及分析出具有意義或洞察的知識。根據此思路,從一開始的數據採集開始,數據可以是線上數據也可以是線下數據,以期通過Data in來實現Value out,即將文本數據進行系統化、客觀性和可量化的分析過程,這也是量化內容分析的三個主要特徵。
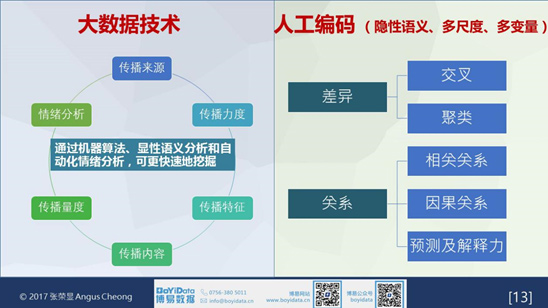
通過大數據技術的輔助,可實現對傳播來源、傳播力度、傳播特徵、傳播內容、傳播量度和情緒分析的快速挖掘,然而,針對隱性語義、多尺度、多變量這些方面則需要通過人工編碼來實現,將兩者有效結合即可解決現實的實務問題,也可以解決在學術論文方面的需求。
在線的內容分析法,是基於傳統的內容分析法,結合機器學習和網絡挖掘技術等,在抽樣、編碼、前測、信度、質量監控、數據分析和可視化各個階段均實現了優化,並可在線實時操作。解決了傳統內容分析法在質量監控方面的空缺,可實時監控編碼時間、速度、績效等。同時,通常困擾研究人員的編碼員之間的信度測試,也可以通過在線的方式,利用算法,快速便捷地實現。
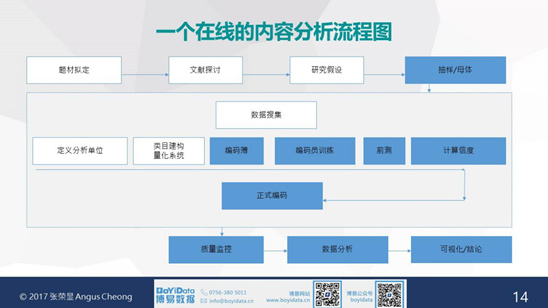
在第十屆PRAD國際學術論壇•第二屆PRSC國際學術年會上發表的學術論文《網絡輿情下的危機公關研究:以港澳地區食品安全問題爲例》,就是運用大數據技術輔助在線內容分析法,在DiVoMiner數據平台上執行整個研究流程,包括設定數據來源、設定概念篩選數據、編碼庫管理、設置類目、前測以計算編碼員之間信度、正式編碼、質量控制、結果分析及可視化呈現等環節。
最後,博易數據資深研究顧問曹文鴛老師,現場演示了雲計算平台DiVoMiner,它是如何通過在線自動化內容分析法、網絡挖掘、機器學習、情緒分析等網絡大數據技術的輔助,結合人工智慧的研究設計及分析,可深度挖掘來自新聞媒體、社交媒體及記錄文本的大數據(包括文字、圖片或視頻)。